DeepSeek AI isn’t just another language model—it represents a major paradigm shift in how AI models are trained and deployed. Here’s what sets it apart:
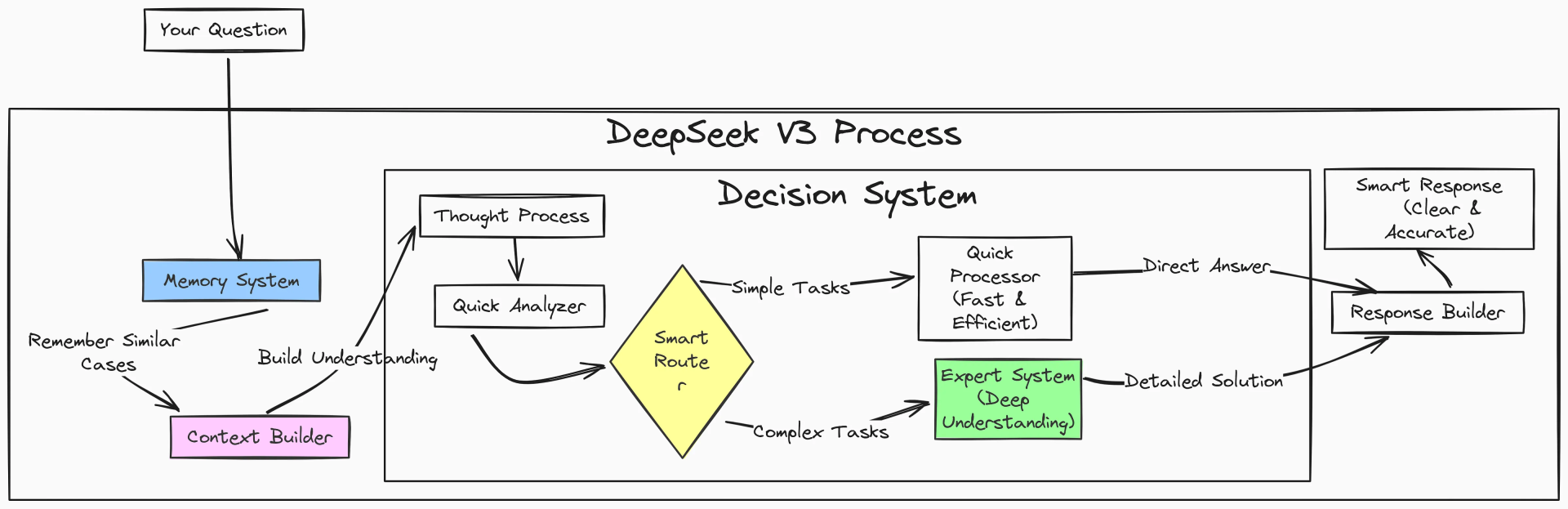
Most AI models provide instant answers based on pre-trained patterns. DeepSeek R1, however, operates
differently. It doesn’t just
spit out an answer—it thinks through the problem step by step.
This is called Chain of Thought reasoning, a method where the AI breaks down complex problems into logical steps before reaching a conclusion. This makes DeepSeek R1 especially powerful for tasks like mathematics, coding, and logical problem-solving.
For example, if you ask a typical AI model a difficult math problem, it might provide an answer without showing its work. DeepSeek, on the other hand, explains each step of its thought process, showing how it arrived at the final answer. This transparency not only improves trust but also makes it far more useful for users who want to understand the logic behind AI-generated responses.
AI training is expensive
—insanely expensive. Companies like OpenAI and Google use tens of thousands of high-performance GPUs to train their models, often racking up
hundreds of millions of dollars in costs.
DeepSeek, however, has managed to train its model using just 2,000 GPUs—a fraction of what its competitors use. For perspective, Meta’s latest AI model, Llama 4, was trained on over 100,000 GPUs. That’s a staggering difference.
What does this mean? AI development doesn’t have to be ridiculously expensive. DeepSeek has shown that with smarter training techniques, AI models can be built and maintained at a fraction of the cost. This could democratize AI development, allowing smaller companies and research teams to compete with tech giants.
DeepSeek R1 uses a
Mixture of Experts (MoE) architecture, a highly efficient design that
activates only the necessary parts of the neural network instead of using the entire model for every task.
Think of it like this: Imagine you’re running a company with a team of specialists—one expert in finance, one in marketing, and one in engineering. Instead of asking every single employee for input on every problem, you only consult the relevant expert for each task. That’s how DeepSeek’s MoE works.
By activating only the relevant “experts” for each request, DeepSeek drastically reduces computational costs while maintaining high performance. This makes it one of the most efficient AI models available today.
Unlike traditional AI models that rely on human-labeled training data (a process known as
Supervised Learning), DeepSeek R1 was trained
primarily through Reinforcement Learning.
This means the model teaches itself. Instead of following a strict set of human-provided rules, it learns through trial and error, receiving rewards for correct answers and penalties for mistakes. Over time, it refines its reasoning and improves its performance autonomously.
This is a game-changer because it allows AI to develop advanced problem-solving skills without requiring massive amounts of labeled data, which is often expensive and time-consuming to obtain.